
 足交 twitter
足交 twitter
新智元报谈
裁剪:桃子 好困
【新智元导读】600万好意思金训出打败GPT-4o大模子,竟被中国团队杀青了!今天,DeepSeek-V3在全网掀起高大风暴,仅凭671B参数在数学代码性能上,堪比海外大模子Claude 3.5 Sonnet。
今夜之间,来自中国的大模子刷屏全网。

DeepSeek-V3,一个领有671B参数的MoE模子,迷糊量每秒高达60 token,比上一代V2平直飙升3倍。
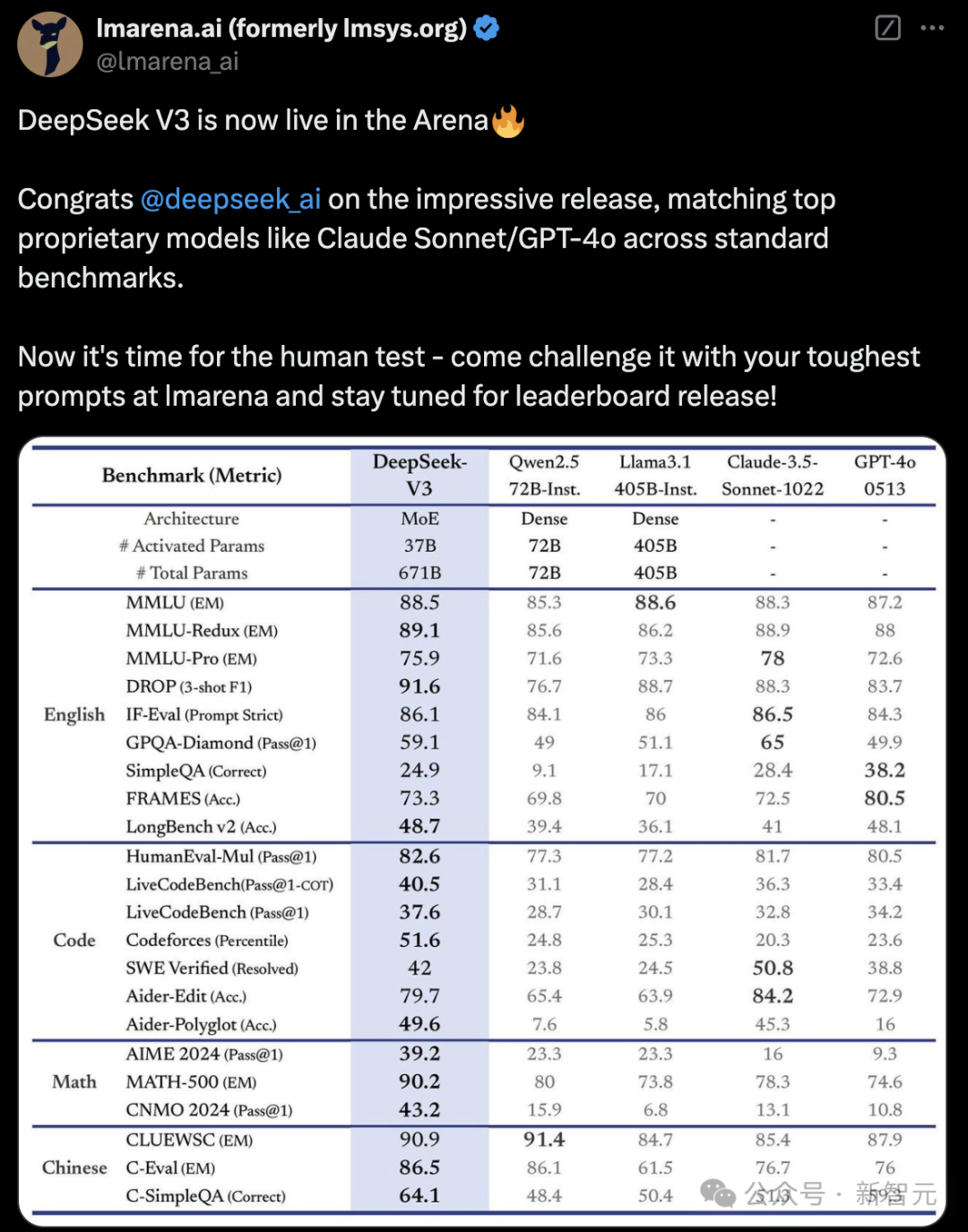
在多项基准测试中,V3性能平直与Claude 3.5 Sonnet、GPT-4o相匹敌。
在数学代码方面,DeepSeek-V3王人备碾压GPT-4o。尤其是汉文身手,全面最初海外的最初大模子。
就看这闪电般的推理速率,就知谈模子有多强了。
值得一提的是,DeepSeek-V3在14.8T高质地token上完成了锤真金不怕火,模子和论文100%开源。

论文地址:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
新模子惊艳出世,透顶掀起了通盘这个词AI圈。业界多位AI大佬,纷繁对此示意恐慌,将重心转向其锤真金不怕火老本GPU之上。
论文中,明确提议了DeepSeek-V3仅使用2048块GPU锤真金不怕火了2个月,况且只消耗了557.6万好意思金。

Karpathy传颂谈,「看成参考,要达到这种级别的身手,时时需要约1.6万个GPU的计较集群。不仅如斯,面前业界正在部署的集群规模致使还是达到了10万个GPU。
比如,Llama 3 405B消耗了3080万GPU小时,而看起来更顽强的DeepSeek-V3却只用了280万GPU小时(计较量减少了约11倍)。
到面前适度,模子在实质足下中的发扬十分出色——不仅在LLM竞技场名列三甲,而且从Karpathy本东谈主的快速测试来看,成果也都很可以。
这阐明,即即是在资源受限情况下,模子也能展现出令东谈主印象深切的策划和工程身手。
这是否意味着前沿LLM不需要大型GPU集群?不是的,但这标明,你必须确保不耗费已有的资源,这个案例很好地阐明了在数据和算法方面还有很大的优化空间」。

另外,贾扬清针对推理提议了几点我方的念念考:
来源最迫切的是,咱们认真干涉了诀别式推理时期。一台单GPU机器(80×8=640G)的显存还是无法容纳通盘参数。诚然更新大显存机器照实可以装下模子,但不管如何,都需要诀别式推理来保证性能和将来膨大。
即使在单个模子中,也需要柔和MoE的负载平衡,因为每次推理只须大致5%的参数激活。
论文中止境提到引入「redundantexpert」办法,恰是为了处罚这个问题。这还是不再是「一个模子多个副本」的问题、而是「每个模子子模块都有多个副本」,然后独处扩缩容。
输入token很容易杀青盈利。把柄个东谈主专科判断,需要多数优化身手使输出token盈利或杀青出入平衡。但若是咱们投诚「软件摩尔定律」,这就不是问题:每18个月单token老本减半。
需要进行分块(tile)或块(block)级别的量化。
等硬件扶植FP4以后,详情还有不少可以玩的名目冷常识:FP4乘法实质上就是个16×16的table lookup等等……

中国模子今夜打败GPT-4o,100%开源
DeepSeek-V3不俗发扬,是在上一代V2进一步升级和迭代。
在基准测试中,数学领域MATH 500上,DeepSeek-V3拿下了90.2高分,比Claude 3.5 Sonnet、GPT-4o超出10分还要多。
同理,在AIME 2024测试中,DeepSeek-V3也赢得了最初上风,飙升近20分。
在代码Codeforces基准上,新模子以51.6分刷新SOTA,比海外大模子跳动30分傍边。
在软件工程SWE-bench Verified基准上,DeepSeek-V3略显失神,Claude 3.5 Sonnet以50.8分碾压通盘模子。
另外,在多说话身手(MMLU-Pro)方面,V3擢升并不赫然。常识问答基准(GPQA-Diamond)上,V3亦然仅次于Claude 3.5 Sonnet。
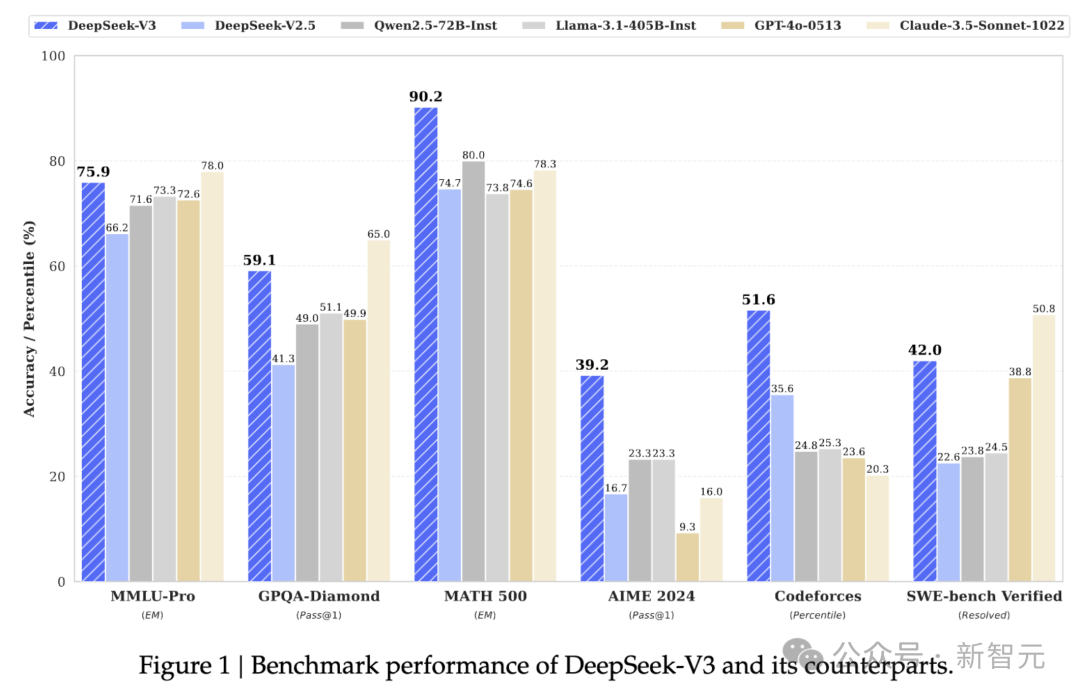
如下这张图表,更翔实地展示了DeepSeek-V3在各样基准测试中的成果。
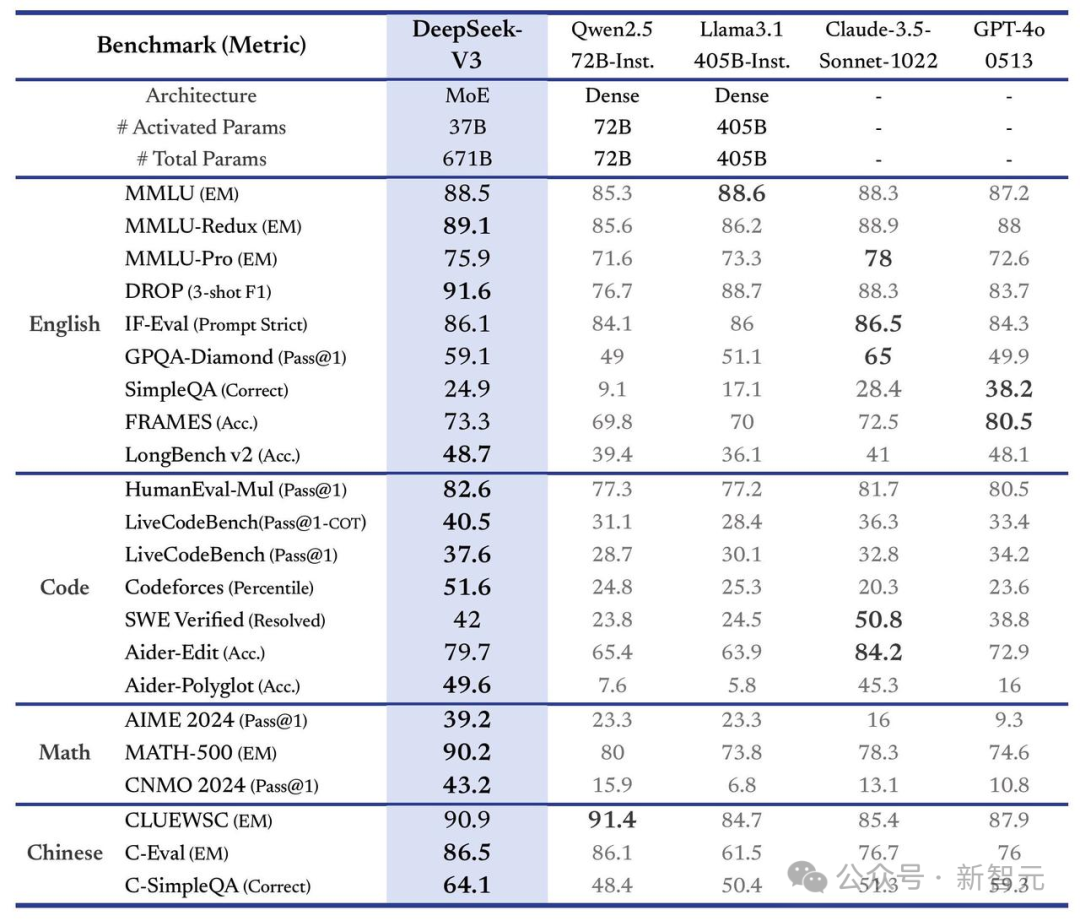
53页工夫阐述中,特比强调了V3的锤真金不怕火老本赢得了最大的打破。
团队有利强调了,新模子的好意思满锤真金不怕火仅需要2.788M个GPU小时。即便如斯,它在锤真金不怕火历程中相等幽闲,莫得际遇过任何不陋习复的loss突增,也莫得实施任何rollback操作。
DeepSeek-V3锤真金不怕火老本如下表1所示,这是背后团队通过优化算法、框架、硬件协同瞎想最终杀青的。
在预锤真金不怕火阶段,模子每锤真金不怕火1万亿token仅需要180K个GPU小时,即在配备2048个GPU的集群上只需3.7天。
因此,DeepSeek-V3预锤真金不怕火阶段耗时不到2个月就完成了,统共消耗2664K个GPU小时。
另外,再加上高下文长度scaling所需的119K GPU小时和后锤真金不怕火的5K GPU小时,由此V3好意思满锤真金不怕火仅消耗2.788M个GPU小时。
团队示意,假定GPU的租用价钱为2好意思元/每GPU小时,DeepSeek-V3总锤真金不怕火老本仅为557.6万好意思元。

那么,究竟是怎样的工夫打破,使得DeepSeek-V3杀青了质的飞升?
锤真金不怕火细节
正如来源所述,DeepSeek-V3是一个顽强的混杂民众模子(MoE),总参数目为为671B,每个token激活37B参数。
它连接秉承了多头潜在谛视力(MLA)来杀青高效推理,以及DeepSeekMoE杀青低老本锤真金不怕火。
这两种架构的上风,还是在上一代V2中得到了考据。
除了基本框架除外,策划东谈主员还秉承了两个稀奇的战略,来进一步增强模子的身手:
秉承无辅助亏本(auxiliary-loss-free)形状来杀青负载平衡,主义是最小化负载平衡对V3性能形成的不利影响。
秉承多token展望锤真金不怕火打算,成果阐明豪迈擢升V3在评估基准上的全体性能。
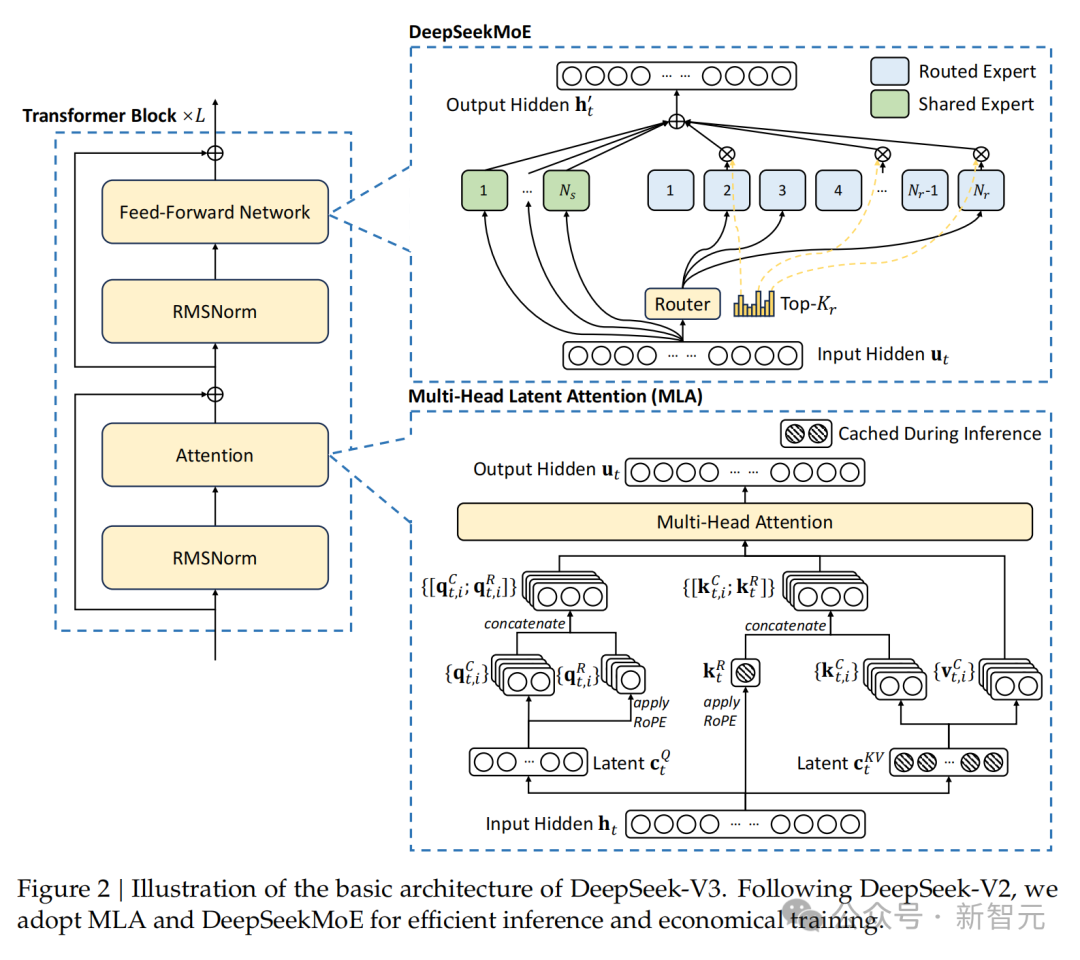
DeepSeek-V3框架
为了杀青高效锤真金不怕火,团队秉承了「FP8混杂精度锤真金不怕火」,并对锤真金不怕火框架进行了全面优化。
通过扶植FP8计较和存储,杀青了锤真金不怕火加快和GPU内存使用的减少。
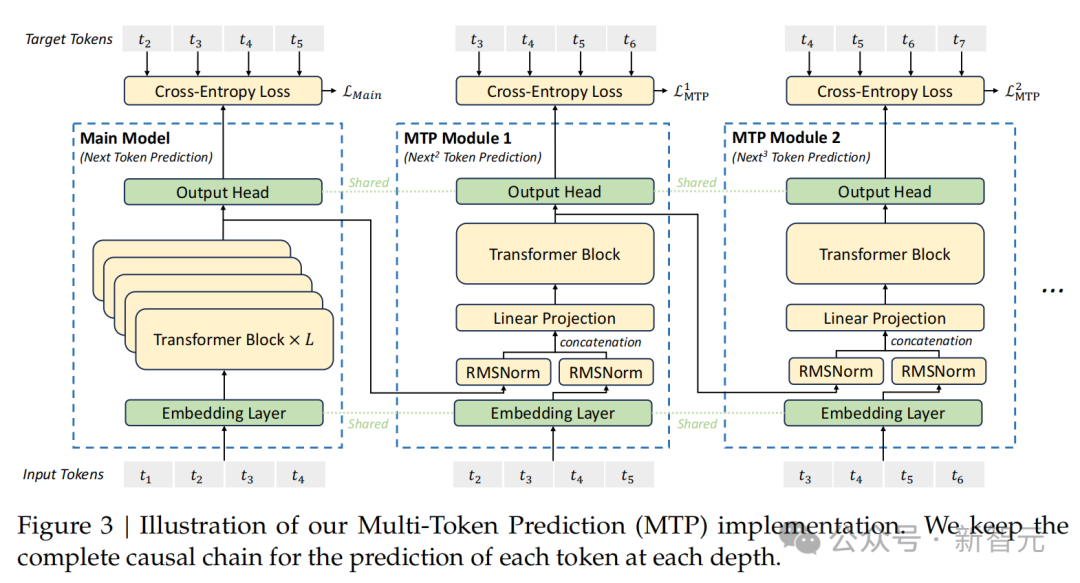
在预锤真金不怕火阶段,DeepSeek-V3在14.8T高质地且各样化的token完成了锤真金不怕火,然后又对模子进行了监督微调、强化学习阶段。
由此,咱们才看了DeepSeek-V3在如上评测中,性能杰出了其他开源模子,并达到了与最初闭源模子十分的性能水平。
五月天小说网友炸锅了
DeepSeek-V3面前还是在官方平台上平直可以测试,而且代码全部开源可以平直下载。
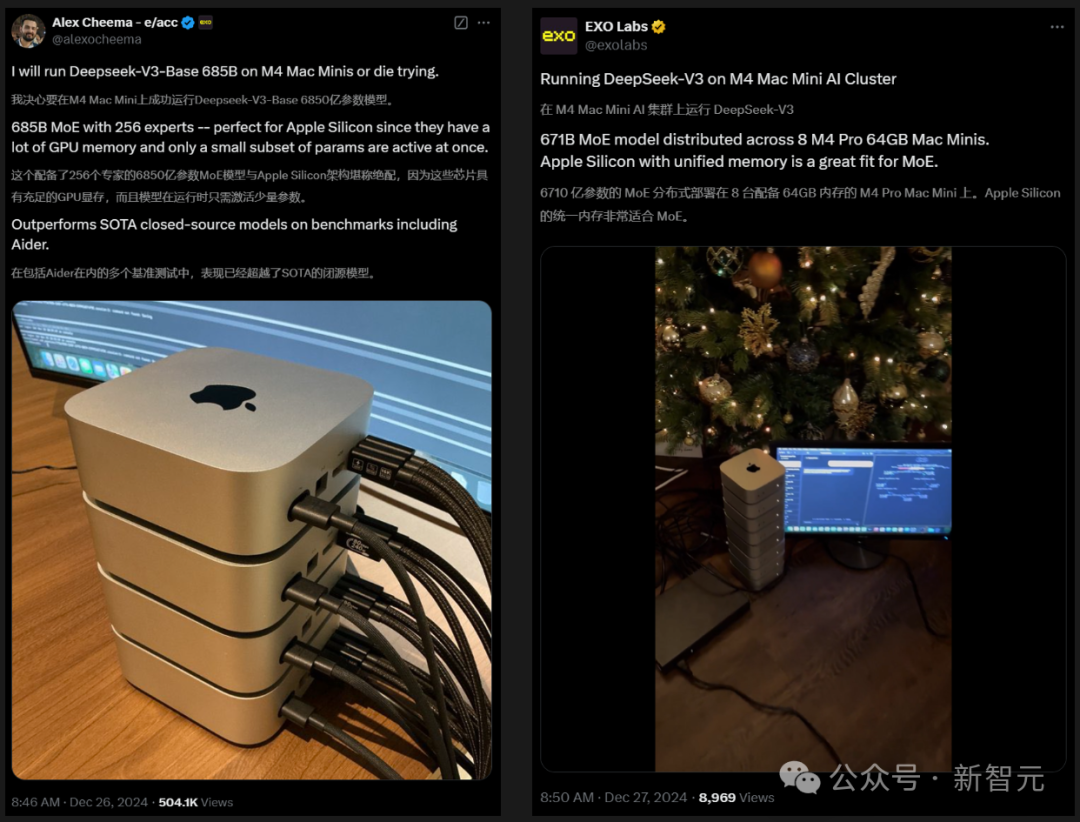
海外AI发热友们纷繁开启了测试,有东谈主平直将4/8个M4 Mac mini堆叠在沿路来驱动DeepSeek-V3了...
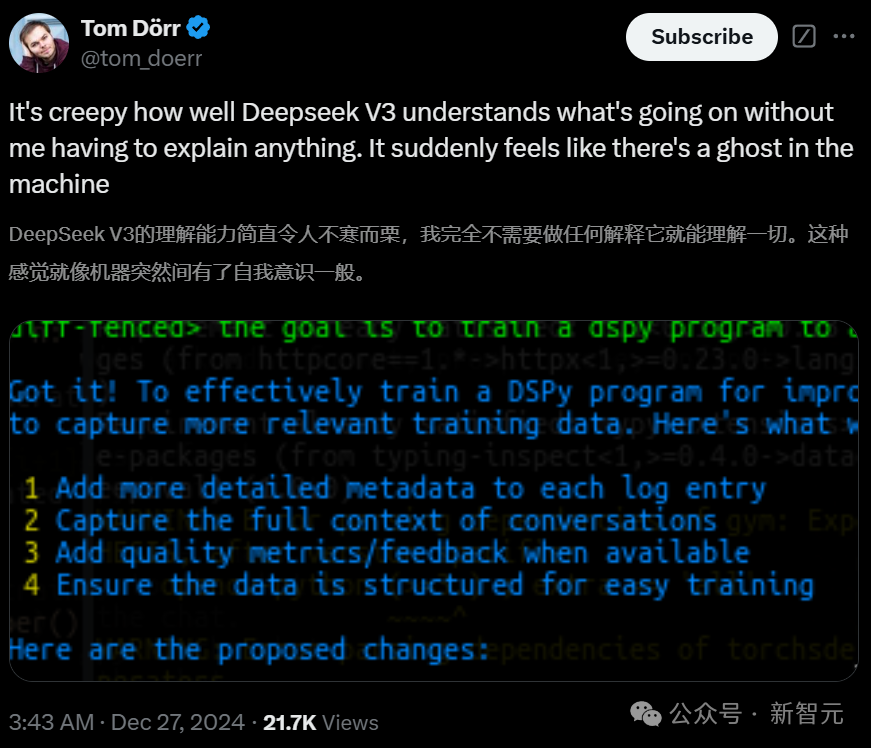
一位建造者惊诧地示意,DeepSeek-V3无需我解释就能如斯准确地阐明一切,这种嗅觉真让东谈主坐立不安。就好像机器里真是住着一个阴灵似的。
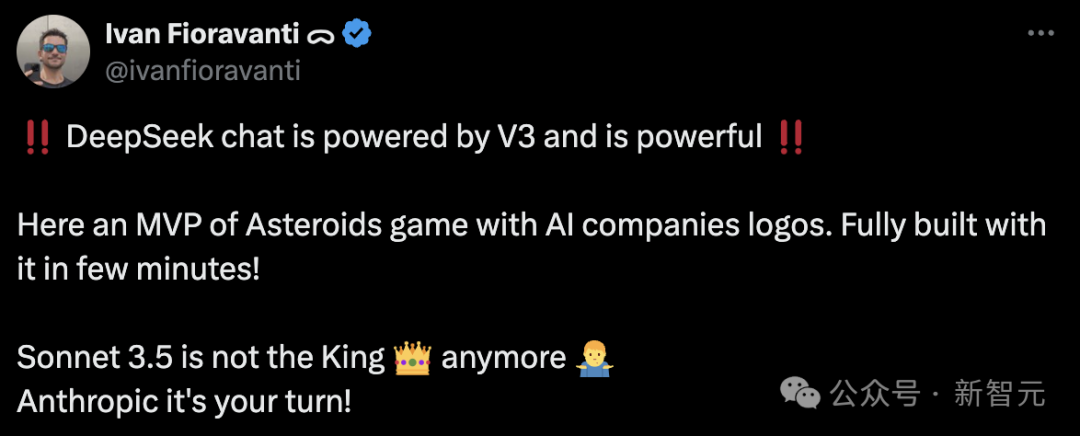
另有建造者通过DeepSeek-V3创建了一个用AI公司logo制作的小行星游戏,分分钟就完成了。
还有的东谈主对用如斯低老本,锤真金不怕火出一个顽强得模子,难以置信。
Stability AI前CEO示意,以每秒60个token(十分于东谈主类阅读速率5倍)的速率全天候驱动DeepSeek v3,每天仅需要2好意思元。
那么,你是要采选一杯拿铁咖啡,照旧一个AI助手呢?
